 |
 |
 |
 |
 |
 |
|
The search system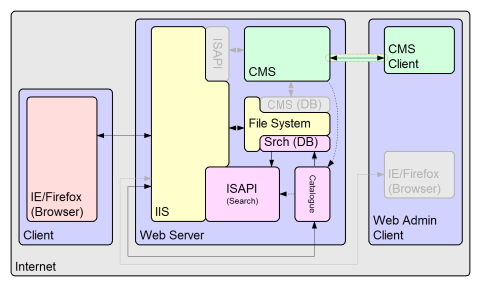
The search system is a simple server side application of three components;
The catalogue tool is responsible for generating the search database file. It runs from the command line on the server, but the CMS described previously has the capacity to securely invoke batch files that run on the server, through it's client application. Such batch files are easily configured to use the catalogue tool, and both generate and update the search database. The console tool is a very simple debugging facility. It merely allows the user the ability to read, and particularly search, the database without the need to access the database through a web page. In normal circumstances it does not need to be used. It can be useful at the early stages of setting up a website, to determine the sort of information one naturally finds in the search database, that may or may not actually be required. Clearly with such a dynamic capability one can tailor ones templates to refine the information that is actually catalogued. The search tool is an IIS ISAPI module which is capable of reading the search database. It performs search on the basis of a simple CGI query that one might submit in the form of an HTTP Get or Post operation, using an HTML form. It has it's own very simple templating scheme which allows the detail of a search response page header/footer to be described. The search module is directly responsible for formatting search output. The search module loads the search database when it is first called, and subsequently uses this database for any future searches. There is a loose link provided between the catalogue and search tools. This merely provides a scheme where the search tool can be forced to reload it's database under the instruction of the catalogue tool, where perhaps the search database has been updated. The database file is a privately defined format. It is generated by the catalogue tool, and operates on the basis of an initial URL. When invoked the catalogue tool will access the internet and retrieve the page presented at that URL. The search tool will then parse that page and separate out both the links and the text information of that page. Some links like those of image data are discarded and others like links to different pages or referenced text information are retained. The text information from a page is built into a digest, and then scanned such that each word is placed into a dictionary within the database. Each dictionary entry links to each of the page digests that were used to define it. The digest is compressed using a private compression algorithm, similar to the popular LZW. The compressed digest is added to the database along with the dictionary. Finally each of the extracted links from the page is tested, and processed in similar way. The catalogue tool is not capable of indexing the whole of the internet, although it would try if it was allowed to. For this reason the tool takes instructions, at invokation, on single URL components to avoid and also URL components that must be present to allow cataloguing to take place. A mechanism is provided to strip session information from URLs that are parsed. In addition it is possible to place comments with specific guide text into any page that the cataloguing tool will exclude from any digest or list of links. When a search query is made, the database dictionary is queried for matches from the query string, and then a probabalistic approach to sorting and truncating search hits is used. Once this list of results is formed, the associated digests are extracted from the database and decompressed. The digest is inspected for the word positions of each of it's query string matches, and again a probabalistic approach is used to trim the digest to the most appropriate section for display. Once all of this information is gathered the results section of the search page is formatted, and the headers and footers appended. |


Copyright © Solid Fluid 2007-2025 |
Last modified: SolFlu Fri, 05 Jun 2009 22:31:14 GMT |