|
|
The content management system (CMS)
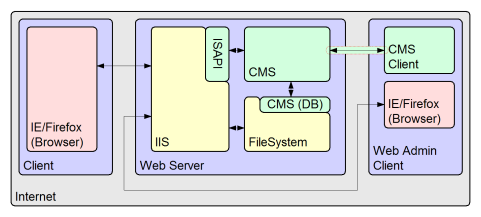
The CMS is a sockets (TCP/IP) based client/server application. On the web server it runs as a background service, and on the client resembles a text editor. The two can communicate and the editor has an explorer style tree control which represents files on the server. It affords the continuous development of a website without the need to do it through a browser. It is simply my opinion that browsers are really great for browsing, but when it comes to actually creating and manipulating website content, a proper "smart client" application is much better, even where it is somewhat basic.
The CMS uses a privately defined secure password authentication scheme, and has basic user management capabilities. This means that as a system administrator you can be sure of who did what. In addition you can be confident that people you don't want, cant do.
The CMS creates a filesystem based database local to the server machine. When a browser makes a request to Microsoft's Internet Information Services (IIS), a Solid Fluid CMS/IIS interface module is requested data by IIS. The CMS returns page data to IIS, and IIS returns it to the browser which requested it. On the face of it, it may seem odd to introduce such a capability, when web pages could be stored in the normal way on disk. Certainly it has a marginal effect on performance, since there is more code to execute, but freeing the documents from the boundaries of the file system allows some significant functional benefits;
- The most obvious benefit is that the files are separated from the standard file system storage scheme, where they might only be accessible on a remote client machine by such schemes as FTP. Windows domains can stretch insecure distances securely, but they can't do such things as will become apparent. FTP has inherent security limitations, and although there are secure versions available they still have relatively poor integration on the client machine.
- Separating the content files into a server local database, allows for the provision of content based metadata. This can benefit in many ways;
- Most important, but perhaps subtle is the idea of permalinking. Permalinks tend to be codified URL's that don't change, and always reference the same end page. A normal URL might be a textual link something like a pathname and a filename. For a human reader these are great, and one would normally want the general arrangement of a website to reflect such links. If someone can remember the text, then they can type what they want into their browser, and get it. The trouble comes when the website changes. Does the request map to the new page or the old page. With permalinking, one has a long cycle of disposal for old page data. Perhaps, one may not delete old pages for a year after they are obsolete. The text based URL takes you to the latest page, the coded permalink URL always takes you to the page you actually saw, whenever you linked to it. The same is true for pages that move. If the page moves, the old text link may become unavailable, but the permalink takes you to the new location for the document.
- Metadata is also a benefit when creating templated pages. Data like the user who modified the page, or the date and time they modified it, can be automatically maintained with the document. Such data can be easily inserted into the template. Search engines love this kind of metadata, because it can help them reduce the amount of processing time they need to expend on processing your page. If the page date hasn't changed since the last time they looked at it, they don't need to look at it again. This is much quicker for them than having to read the page and understand it.
- Metadata is also useful for templating in other ways. A page that you might generate and would work in a browser on your machine would be different for identical browser output on the server. One of the more unusual capabilities of this content management system is that it has the capacity to take a page that works on a local machine, and automatically convert it to a page that is correct for use on the server. It knows where the links are on the client machine, so it can automatically move content that is not already on the server, to the server. Where linked content is already on the server, it simply modifies the link to point to the content on the server. Although your page is composed of many files (links and images) you can treat it just as one.
- This is also useful for search engine friendly keyword metatags. On the client machine the metatags would be in the page header, but on the templated server those tags must appear in the template header. When a page is uploaded, these metatags can be automatically read and stored for insertion into the template header.
- Obviously the metadata and page have been broken into separate entities for use on the server. The server knows what your original page looked like so when you ask for it back, it rebuilds the page and gives it back to you. My SGML parser is quite tame - you don't get a Microsoft mess back, unless perhaps you gave it one!
In a general sense the Solid Fluid application libraries take care of the difficult work, which is reading, understanding, and maintaining the website content. The actual templates that format the website output are built in PHP, and extracting the information is trivial task using a very simple PHP API. The API is solely PHP based but it would be a simple task to integrate it with Perl, Tcl or even .NET. Our output is not currently cached in PHP, but we don't get that much traffic. To do so would not be hard and is made easier by the wealth of, and easy access to, metadata. |







